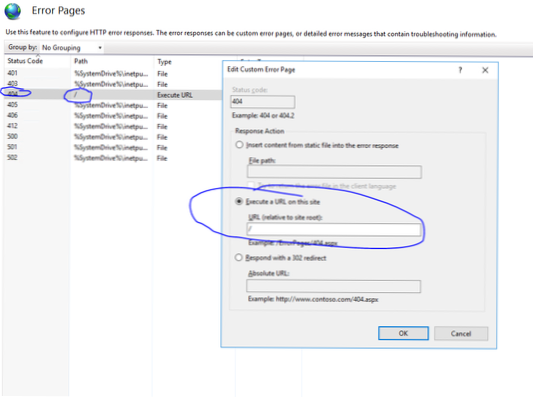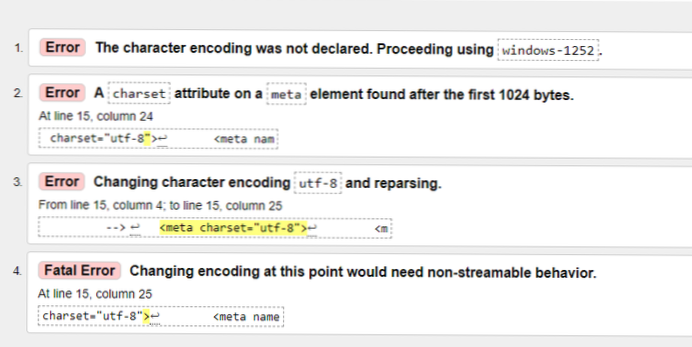
- Hvordan blir jeg kvitt UTF-8-feilen?
- Hva er UTF8-feil?
- Hvordan endrer jeg kodingen til UTF-8?
- Hvordan lagres UTF8?
- Hvordan fikser jeg Unicode-problemer?
- Hvilke tegn som ikke er tillatt i UTF-8?
- Hva betyr UTF-8 i HTML?
- Hvorfor erstattet UTF-8 ascii?
- Er UTF-8 det samme som Ascii?
- Hva er forskjellen mellom ANSI og UTF-8?
- Hvorfor brukes UTF-8?
- Hva UTF-8 betyr?
Hvordan blir jeg kvitt UTF-8-feilen?
2 svar
- bruk et tegnsett som godtar byte som iso-8859-15, også kjent som latin9.
- hvis utdata skal være utf-8 men inneholder feil, bruk feil = ignorere -> fjerner lydløst ikke utf-8 tegn, eller feil = erstatt -> erstatter ikke utf-8 tegn med en erstatningsmarkør (vanligvis ? )
Hva er UTF8-feil?
UTF-8 er det dominerende tegnkodningsformatet på Internett. Denne feilen oppstår fordi programvaren du bruker lagrer filen i en annen type koding, for eksempel ISO-8859, i stedet for UTF-8. Det er forskjellige løsninger du kan bruke til å endre filen til UTF-8-koding.
Hvordan endrer jeg kodingen til UTF-8?
Klikk Verktøy, og velg deretter Webalternativer. Gå til fanen Koding. I rullegardinmenyen for Lagre dette dokumentet som: velg Unicode (UTF-8). Klikk OK.
Hvordan lagres UTF8?
Når programvare som leser UTF-8 kommer over en byte som begynner med 1, teller den hvor mange 1 som følger før du møter en 0. ... Så en byte av formen 110xxxxx sier at de første fem bitene av et Unicode-tegn er lagret på slutten av denne byten, og resten av bitene kommer i neste byte.
Hvordan fikser jeg Unicode-problemer?
Det første trinnet mot å løse ditt Unicode-problem er å slutte å tenke på typen< 'str'> som lagring av strenger (det vil si sekvenser av menneskelesbare tegn, a.k.en. tekst). Begynn i stedet å tenke på typen< 'str'> som en container for byte.
Hvilke tegn er ikke tillatt i UTF-8?
Merk at et bytebestillingsmerke (BOM) U + FEFF, også kalt null-bredde no-break space (ZWNBSP), ikke kan vises ukodet i UTF-8 - byte 0xFF og 0xFE er ikke tillatt i gyldig UTF-8. En kodet ZWNBSP kan vises i en UTF-8-fil som 0xEF 0xBB 0xBF, men stykklisten er helt overflødig i UTF-8.
Hva betyr UTF-8 i HTML?
charset = UTF-8 står for Character Set = Unicode Transformation Format-8. Det er en oktett (8-bit) tapsfri koding av Unicode-tegn. Disse bør belyse forståelsen i nettutvikling og skripting mer.
Hvorfor erstattet UTF-8 ascii?
UTF-8 erstattet ASCII fordi den inneholdt flere tegn enn ASCII som er begrenset til 128 tegn.
Er UTF-8 det samme som Ascii?
For tegn representert med 7-biters ASCII-tegnkoder, er UTF-8-representasjonen nøyaktig ekvivalent med ASCII, slik at gjennomsiktig rundtursmigrering. Andre Unicode-tegn er representert i UTF-8 med sekvenser på opptil 6 byte, selv om de fleste vesteuropeiske tegn bare krever 2 byte3.
Hva er forskjellen mellom ANSI og UTF-8?
ANSI og UTF-8 er to tegnkodingsskjemaer som er mye brukt på et eller annet tidspunkt. Hovedforskjellen mellom dem er bruk da UTF-8 alt annet enn har erstattet ANSI som kodingsskjema. ... Siden ANSI bare bruker en byte eller 8 bits, kan den bare representere maksimalt 256 tegn.
Hvorfor brukes UTF-8?
Hvorfor bruke UTF-8? En HTML-side kan bare være i en koding. Du kan ikke kode forskjellige deler av et dokument i forskjellige kodinger. En Unicode-basert koding som UTF-8 kan støtte mange språk og kan ta imot sider og skjemaer i en hvilken som helst blanding av disse språkene.
Hva UTF-8 betyr?
UTF-8 Grunnleggende. UTF-8 (Unicode Transformation – 8-bit) er en koding definert av International Organization for Standardization (ISO) i ISO 10646. Den kan representere opptil 2097152 kodepunkter (2 ^ 21), mer enn nok til å dekke de nåværende 1.112.064 Unicode-kodepunktene.